
What is Search Engine. How Does It Work in 2026?
Topic 1 Introduction
What is Search Engine ?
A Search Engine is a software system that helps users find information on the internet by entering keywords or queries. It works by crawling, indexing, and ranking web pages to display the most relevant and useful results to the user.
How Search Engines Work (Step-by-Step)
Search engines like Google follow a structured process:
📊 Diagram: Search Engine Workflow
[ Website ]
↓
(1) Crawling
↓
(2) Indexing
↓
(3) Ranking
↓
[ Search Results Page ]1️⃣ Crawling (Discovery Phase)
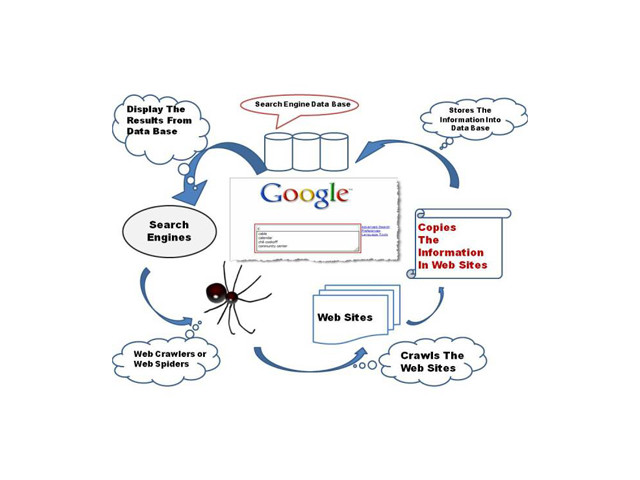
- Google uses bots called crawlers or spiders
- These bots scan websites and follow links
📌 Example:
Page A → Page B → Page C
↓ ↓
Google Bot visits all pages
👉 If your site is not crawlable, it won’t appear in search results.
2️⃣ Indexing (Storage Phase)
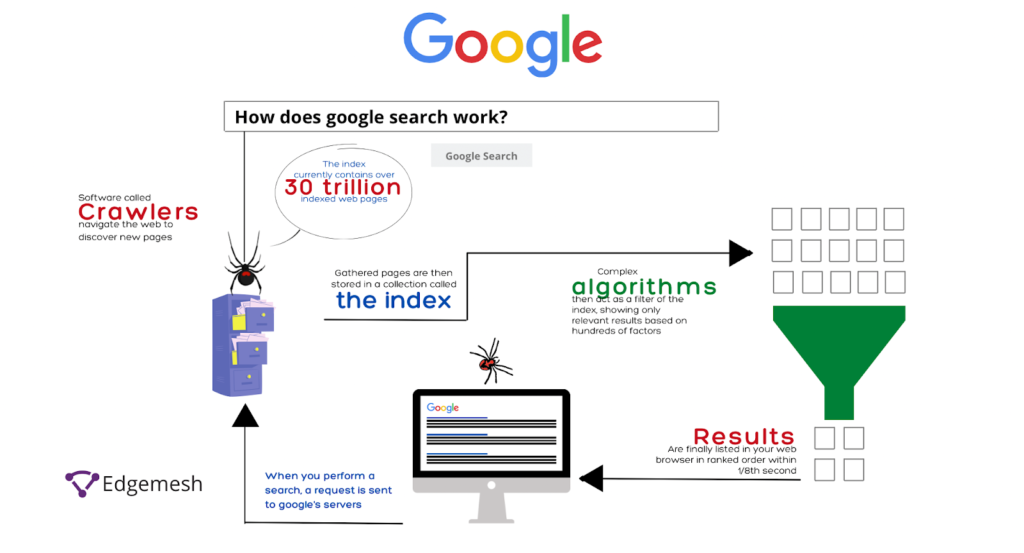
- After crawling, Google stores your page in its database (index)
- It understands:
- Content
- Images
- Keywords
- Structure
📊 Diagram:
[ Crawled Pages ]
↓
[ Google Index Database ]
↓
Stored & Organized Content
👉 If your page is not indexed, it cannot rank.
3️⃣ Ranking (Display Phase)

- Google ranks pages based on relevance and quality
📊 Diagram:
User Search: "Best laptops" ↓ Google Algorithm Analysis
↓ Rank #1 → Best Match
Rank #2 → Second Best
Rank #3 → Third Best
Types of Search Engine
1️⃣ Crawler-Based Search Engines
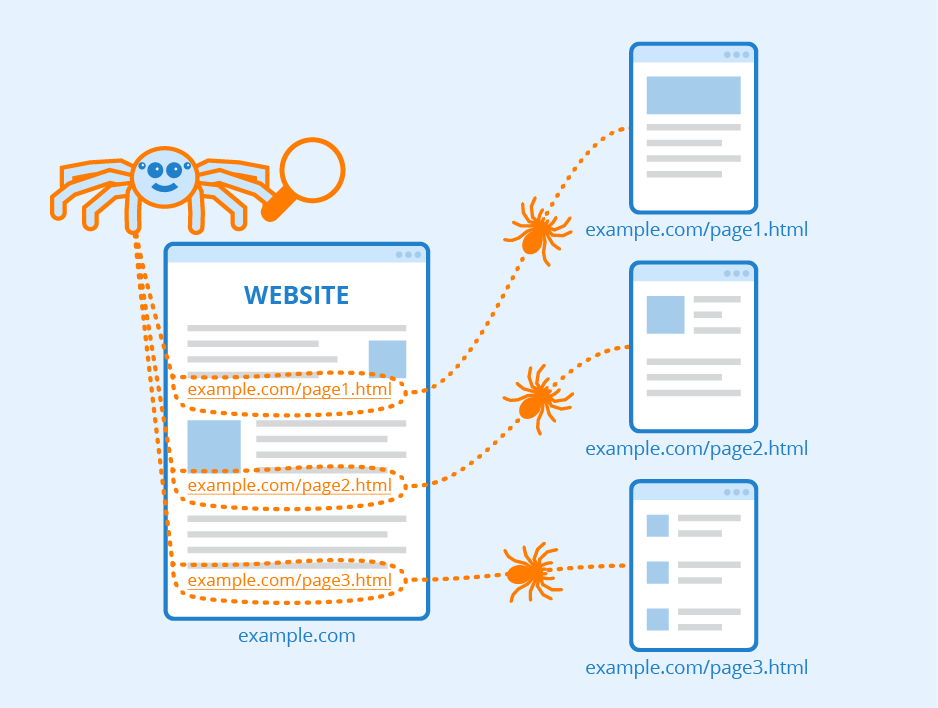
Crawler-based search engines are the most widely used type today. They rely on automated programs called crawlers or spiders to scan and index web pages across the internet.
🔍 How it works:
- Bots (crawlers) visit web pages
- They analyze and store content in a database (index)
- Results are displayed based on relevance to the user’s query
✅ Examples:
- Bing
- Yahoo
👉 These are the most important search engines for SEO.
2️⃣ Directory-Based Search Engines

Directory-based search engines organize websites into categories, and listings are manually reviewed and added by humans.
🔍 How it works:
- Websites are submitted manually
- Human editors review and categorize them
- Users browse categories to find relevant sites
✅ Examples:
- DMOZ (Open Directory Project)
- Yahoo Directory (historical)
👉 These are rarely used today but important for understanding SEO history.
3️⃣ Hybrid Search Engines

Hybrid search engines combine both crawler-based and directory-based methods to deliver more accurate results.
🔍 How it works:
- Uses crawlers to collect data
- May include human-reviewed or curated content
- Combines multiple data sources for better results
✅ Examples:
- Yahoo
👉 Most modern search engines follow this hybrid approach.
4️⃣ Meta Search Engines


Meta search engines do not have their own database. Instead, they gather results from multiple search engines and display them in one place.
🔍 How it works:
- Sends user queries to multiple search engines
- Collects and combines the results
- Displays aggregated results to the user
✅ Examples:
- Dogpile
- Startpage
👉 Useful for getting results from multiple sources at once.